My name is Jonathan, and I have a coding obsession.
I’ll admit it, the Hadleyverse has ruined me. I can no longer read a blog post or stackoverflow question in base R and leave it be. There are improvements to make, and I’m somewhat sure that I know what they are. Most of them involve dplyr. Many involve data.table. Some involve purrr.
This one came up on R-bloggers today (which leads back to MilanoR) and seemed like a good opportunity. The problem raised was; given a list of data.frames, can you create a list of the variables sorted into those data.frames? i.e. can you turn this
df_list_in <- list (
df_1 = data.frame(x = 1:5, y = 5:1),
df_2 = data.frame(x = 6:10, y = 10:6),
df_3 = data.frame(x = 11:15, y = 15:11)
)into this
df_list_out <- list (
df_x = data.frame(x_1 = 1:5, x_2 = 6:10, x_3 = 11:15),
df_y = data.frame(y_1 = 5:1, y_2 = 10:6, y_3 = 15:11)
)That looks like a problem I came across recently. Let’s see…
I managed to replace that function – which, while fast, is a little obtuse and difficult to read – with essentially a one-liner
df_list_in %>% purrr::transpose() %>% lapply(as.data.frame)## $x
## df_1 df_2 df_3
## 1 1 6 11
## 2 2 7 12
## 3 3 8 13
## 4 4 9 14
## 5 5 10 15
##
## $y
## df_1 df_2 df_3
## 1 5 10 15
## 2 4 9 14
## 3 3 8 13
## 4 2 7 12
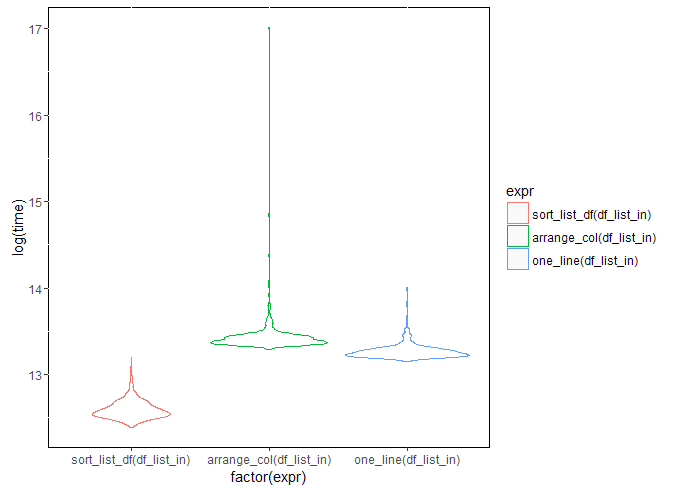
## 5 1 6 11You may now proceed to argue over which is easier/simpler/more accessible/requires less knowledge of additional packages/etc… If you ask me, it’s damn-near perfect as long as you can place a cursor on transpose in RStudio and hit F1 which will bring up the purrr::transpose help menu and explain exactly what is going on. Anyway, how does it compare? Here’s Michy’s graph (formatting updated and my function added)
and then, just for fun (and because I wanted an excuse to try it out) here’s a yarrr::pirateplot of the same data
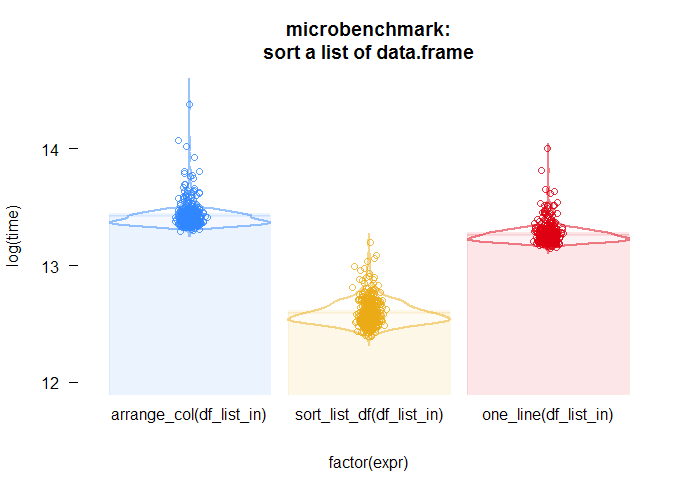
My one-line function (without the magrittr syntactical sugar) does slightly better than the arrange_col function (on average), but has a lot less up-front code and is more readable (to me at least). The performance of any of these three doesn’t seem like it would have trouble scaling for any practical use-case.
Scaling up the problem to a list of 100 data.frames each with 1000 observations of 50 variables, the same result pans out as shown in the above microbenchmark and pirateplot below
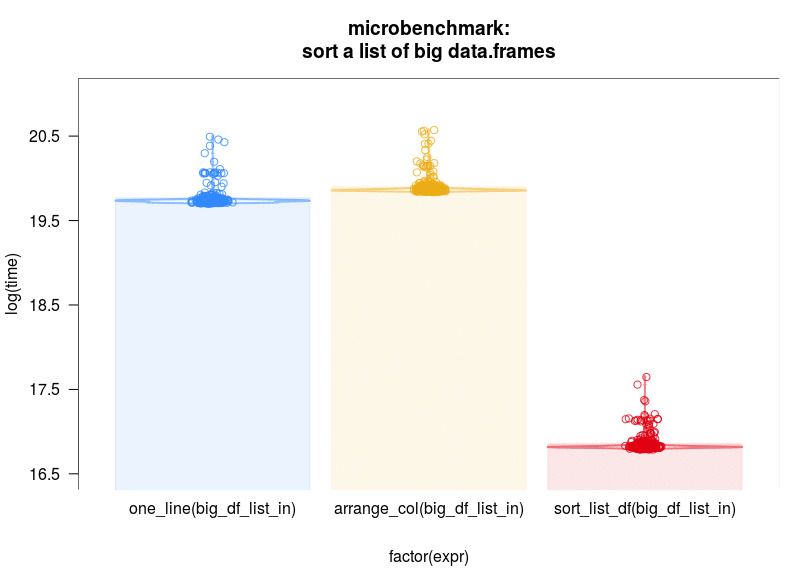
On the giant example (100 data.frames of 1000 observations of 50 variables) the difference is 20ms vs 380ms. Honestly, I don’t know what I’d do with the additional 360ms, but chances are I’d just waste them. I’ll take the efficient code on this one.
Can you do even better than the one-liner? Spot a potential issue? Have I made a mistake? Got comments? You know what to do.
devtools::session_info()
## ─ Session info ──────────────────────────────────────────────────────────
## setting value
## version R version 3.5.2 (2018-12-20)
## os Pop!_OS 19.04
## system x86_64, linux-gnu
## ui X11
## language en_AU:en
## collate en_AU.UTF-8
## ctype en_AU.UTF-8
## tz Australia/Adelaide
## date 2019-08-13
##
## ─ Packages ──────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 3.5.2)
## backports 1.1.4 2019-04-10 [1] CRAN (R 3.5.2)
## blogdown 0.14.1 2019-08-11 [1] Github (rstudio/blogdown@be4e91c)
## bookdown 0.12 2019-07-11 [1] CRAN (R 3.5.2)
## callr 3.3.1 2019-07-18 [1] CRAN (R 3.5.2)
## cli 1.1.0 2019-03-19 [1] CRAN (R 3.5.2)
## crayon 1.3.4 2017-09-16 [1] CRAN (R 3.5.1)
## desc 1.2.0 2018-05-01 [1] CRAN (R 3.5.1)
## devtools 2.1.0 2019-07-06 [1] CRAN (R 3.5.2)
## digest 0.6.20 2019-07-04 [1] CRAN (R 3.5.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 3.5.2)
## fs 1.3.1 2019-05-06 [1] CRAN (R 3.5.2)
## glue 1.3.1 2019-03-12 [1] CRAN (R 3.5.2)
## htmltools 0.3.6 2017-04-28 [1] CRAN (R 3.5.1)
## knitr 1.24 2019-08-08 [1] CRAN (R 3.5.2)
## magrittr * 1.5 2014-11-22 [1] CRAN (R 3.5.1)
## memoise 1.1.0 2017-04-21 [1] CRAN (R 3.5.1)
## pkgbuild 1.0.4 2019-08-05 [1] CRAN (R 3.5.2)
## pkgload 1.0.2 2018-10-29 [1] CRAN (R 3.5.1)
## prettyunits 1.0.2 2015-07-13 [1] CRAN (R 3.5.1)
## processx 3.4.1 2019-07-18 [1] CRAN (R 3.5.2)
## ps 1.3.0 2018-12-21 [1] CRAN (R 3.5.1)
## purrr 0.3.2 2019-03-15 [1] CRAN (R 3.5.2)
## R6 2.4.0 2019-02-14 [1] CRAN (R 3.5.1)
## Rcpp 1.0.2 2019-07-25 [1] CRAN (R 3.5.2)
## remotes 2.1.0 2019-06-24 [1] CRAN (R 3.5.2)
## rlang 0.4.0 2019-06-25 [1] CRAN (R 3.5.2)
## rmarkdown 1.14 2019-07-12 [1] CRAN (R 3.5.2)
## rprojroot 1.3-2 2018-01-03 [1] CRAN (R 3.5.1)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 3.5.1)
## stringi 1.4.3 2019-03-12 [1] CRAN (R 3.5.2)
## stringr 1.4.0 2019-02-10 [1] CRAN (R 3.5.1)
## testthat 2.2.1 2019-07-25 [1] CRAN (R 3.5.2)
## usethis 1.5.1 2019-07-04 [1] CRAN (R 3.5.2)
## withr 2.1.2 2018-03-15 [1] CRAN (R 3.5.1)
## xfun 0.8 2019-06-25 [1] CRAN (R 3.5.2)
## yaml 2.2.0 2018-07-25 [1] CRAN (R 3.5.1)
##
## [1] /home/jono/R/x86_64-pc-linux-gnu-library/3.5
## [2] /usr/local/lib/R/site-library
## [3] /usr/lib/R/site-library
## [4] /usr/lib/R/library