Can you predict the output from this code?
printStr <- function(str) paste(str, collapse="")
set.seed(12173423); x <- sample(LETTERS, 5, replace=TRUE)
set.seed(7723132);y <- sample(LETTERS, 5, replace=TRUE)
paste(printStr(x), printStr(y))Okay, the first bit is straightforward; it’s a function that puts two string together into one. The next two lines appear to provide a random integer to the set.seed function then sample the pool of LETTERS 5 times with replacement. The last line uses the function from the first line to combine those samples of letters together into one string. Easy enough. Looks like it will produce a random string. Give it a try… go on, the seeds should make it reproducible.
[1] "HELLO WORLD"Whoa! What are the odds of that!?! Of all the possible letters we could have sampled, we get that!
Okay, yes, it’s rigged. Pretty neat choice of values for set.seed there, right? I came across the Java variant of this via StackOverflow’s ‘Hot Network Questions’ sidebar (a rabbit-hole equal in depth to a Wikipedia wiki-hole). The seeds just happen to be ones that when sampled 5 times with replacement produce the right values to extract those letters in order. That seems simple enough until you want to find them.
Update (2019): With R 3.6 the random number generator (RNG) has been updated to avoid a particular bug, the result of which is that this entire process will be invalid for that R version. This will still work as advertised in versions prior to 3.6, but the same seed will produce different strings in 3.6 and above.
The possible combinations of 5 letters, chosen with replacement, from the pool of 26 is \(26^5\) which is a lot, but not insanely many. I work with multi-million row datasets frequently enough. So, we could just run a loop over all integers (set.seed rounds to nearest integer anyway; refer to ?set.seed), set the seed to that value, and save the sampled letters. The first combination will be
set.seed(1L)
sample(LETTERS, 5, replace=TRUE)## [1] "G" "J" "O" "X" "F"So, we write a loop and iterate over the seed, saving the outputs. But wait, you may wonder, what’s to guarantee that we don’t get the same sample twice? Nothing. It’s a random sample starting from a different seed every time; there’s no control over the results after the fact. A quick check confirms this; here’s a duplicate of the first record appearing at seed 3415066L
set.seed(1L);sample1 <- sample(LETTERS, 5, replace=TRUE)
set.seed(3415066L); sample2 <- sample(LETTERS, 5, replace=TRUE)
identical(sample1, sample2)## [1] TRUESo, set.seed(1L) produces the same 5 letter sample as set.seed(3415066L). There’s definitely duplicates of other combinations between those two too. Okay, so we’re not going to be limited to \(26^5\). How many though? Who knows? What’s the distribution of duplication? Without knowing how many we need to try for, we can take the upper limit and go for that; on my machine I get
.Machine$integer.max## [1] 2147483647which is certainly a bigger number, but not out of the realm of possibility.
To make life easier, we can split the problem up. It’s “embarrassingly parallel” (each iteration is completely independent of the others) so it’s perfect for parallelisation. If you haven’t read Drew Schmidt a.k.a wrathematics’ semi-NSFW guide to Parallelism, R, and OpenMP then stop reading this and go read that.
You’re back, great. Let’s assume for now that you too have access to a big, fast computer and want to parallelise the loop over all positive integers. If you’re lucky, it’s as easy as
library(parallel)
cl <-
makeCluster(7) ## 8-core machine, leave one out to remain stable
clusterApply(cl, seq(1, (.Machine$integer.max - 1), 1e7), function(x) {
wordvec <- data.frame(word = character(1e7L), seed = integer(1e7L))
for (iloop in 1:(1e7)) {
iseed <- x + iloop - 1
if (abs(iseed) < .Machine$integer.max) {
set.seed(iseed)
wordvec[iloop, "word"] <-
paste0(LETTERS[sample(26, 5, replace = TRUE)], collapse = "")
wordvec[iloop, "word"] <- iseed
}
}
write.csv(wordvec, file = paste0("seeded_words_", as.character(x), ".csv"))
}
})but life’s not that easy. This is slow as a week of Mondays. For starters, updating the data.frame this many times will probably exhaust your RAM. This was run on a machine with 32GB available, and it got full, fast. Writing out large .csv files is slow, and given that each of them has ten million rows, the 215 files aren’t particularly small; there are a lot of duplicate entries.
We can make this better with a few adjustments;
library(parallel)
cl <-
makeCluster(7) ## 8-core machine, leave one out to remain stable
clusterApply(cl, seq(1, (.Machine$integer.max - 1), 1e7), function(x) {
library(data.table)
wordvec <- data.table(word = character(1e7L), seed = integer(1e7L))
for (iloop in 1:(1e7)) {
iseed <- x + iloop - 1
if (abs(iseed) < .Machine$integer.max) {
set.seed(iseed)
set(
wordvec,
i = iloop,
j = "word",
value = paste0(LETTERS[sample(26, 5, replace = TRUE)], collapse = "")
)
set(wordvec,
i = iloop,
j = "seed",
value = iseed)
}
}
unique_wordvec <- unique(wordvec, by = "word")
save(unique_wordvec,
file = paste0("seeded_words_", as.character(x), ".rds"))
}
})Using data.table means that the set() operations are all in-memory and this alone speeds up the loops. Removing duplicates using unique (now dispatched for data.table) and saving as a compressed binary .rds file makes this a little less bulky. All in all, this can be completed in a few hours on a decent enough machine. I did try using feather for the saving of files and my early tests using smaller subsets showed it to be amazingly fast. Unfortunately there are still some bugs to be ironed out of that package for large files/lots of rows, and my 215 files ended up small, but unreadable.
Given that there’s only \(26^5 = 11881376\) combinations that we’re looking for, depending on how often duplicates come up, we probably don’t need all the results. I’ll save you the trouble and let you know that the loop only needs to go up to at most, 113449118. Reading all of the files back in and merging them again requires some careful considerations. R isn’t too keen on creating objects larger than 2GB, so we can’t really just merge 113449118 lines of data. Taking it step-wise, I managed to get it to work
library(data.table)
library(dplyr)
load("seeded_words_1.rds") ## load the first file
bigdf <-
unique_wordvec## objects were saved as unique_wordvec so save ## to a new name to avoid overwriting
rm(unique_wordvec)## then drop the saved version
allfiles <- list.files(pattern = "01.rds")
## files were saved as 'seeded_words_X.rds' where x was steps of 1e7
## sorting alphabetically gives the wrong order
for (file in allfiles[order(as.numeric(sub("\\.rds", "", sub(
"[a-z_]*", "", allfiles
))))]) {
cat(paste0("** Processing file ", file, "\n")) ## show notifications on the screen
load(file)
bigdf <-
unique(data.table(bind_rows(bigdf, unique_wordvec)), by = "word") ## drop duplicates as we go
rm(unique_wordvec)
if (nrow(bigdf) &
amp
gt
= 26 ^ 5) {
cat(paste0("** Processing OUTPUT file.\n"))
save(bigdf, file = "all_seeded_words.rds")
stop()
}
}This results in a 75MB .rds of all unique combinations of 5 letters sampled with replacement, and the seed that generates them. Not particularly share-able or convenient. We’re mainly interested in actual words. We can filter this list down to English words if we can think of some way to do that (with the associated assumptions and limitations that may bring). Here’s one R option:
library(ScrabbleScore)
words <- bigdf[is.twl06.word(bigdf$word), ]This filters the generated 5-letter words against a Scrabble Official Tournament and Club Word List which is as close as I can be bothered getting to ‘English’ words. What’s left is a list of 8938 5-letter words with their associated generating seeds. Sure enough, filtering the twl06 wordlist down to the 5-letter words gives exactly that many; we’ve generated all the 5-letter words in that data set. Cool. What were we hoping to do with it? Oh, right.
print(words["HELLO"])
#> 1: HELLO 12173423
print(words["WORLD"])
#> 1: WORLD 7723132There we go, the seeds used in the original question for this post. If we wanted, we could write other words or phrases in this way.
set.seed(5360994); x <- sample(LETTERS, 5, replace=TRUE)
set.seed(21732771); y <- sample(LETTERS, 5, replace=TRUE)
paste(printStr(x), printStr(y))## [1] "STATS RULES"We might be interested in what the distribution of unique, English words looks like. Here you go;
library(ggplot2)
gg <- ggplot(words, aes(x=seq_along(seed), y=seed)) gg <- gg + geom_point(alpha=0.6, col="steelblue1", pch=20, size=2) gg <- gg + theme_bw()
gg <- gg + labs(title="Seed that generates unique, English words", subtitle="Filtered as valid Scrabble TW06 words",
caption="https://en.wikipedia.org/wiki/Official_Tournament_and_Club_Word_List",
x="Index",
y="Seed")
ggI’ve converted that using the excellent plotly::ggplotly() function so you can mouseover each point to see the corresponding word.
Fairly uniform looking in that plot. How about the density?
library(ggplot2)
gv <- ggplot(words, aes(x=factor(0), y=seed)) gv <- gv + geom_violin(fill="steelblue1") gv <- gv + theme_bw()
gv <- gv + theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank())
gv <- gv + labs(title="Violin plot of seed that generates unique, English words", subtitle="Filtered as valid Scrabble TW06 words",
caption="https://en.wikipedia.org/wiki/Official_Tournament_and_Club_Word_List",
y="Seed")
gv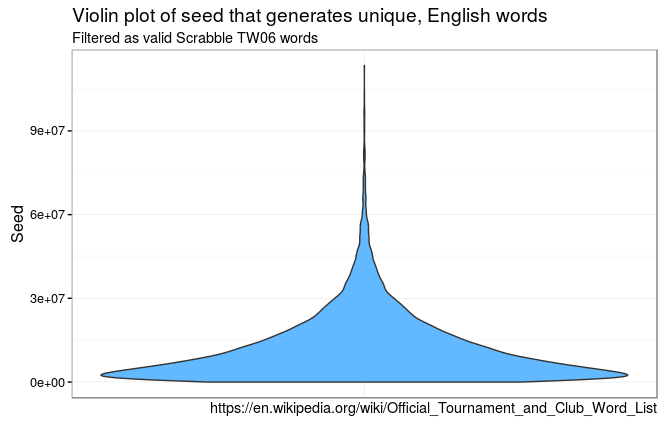
which looks pretty nicely vanishing as more duplicates are produced.
Finally, what about the distribution by starting letter?
Unsurprisingly; not many words starting with “X” (13) and lots starting with “S” (1084). The last word produced (the one with the largest unique seed before we run out of unique words) is “HUTCH” at 113449118.
Can we do anything else with this? The first thing that comes to mind is using this to encode a message. This method is reminiscent of a hash function; it takes some data and via a 1-way mechanism, produces an encoded message. Of course, the 1-way nature of this takes a word and encodes it to an integer that can’t be easily predicted, so hopefully your message is all integers. Many reasons make this a bad idea to actually use for this purpose. The first being that in the world of digital security, if you’re thinking of rolling your own, you’re setting yourself up for trouble. Much smarter people than you or I have spent a lot of time getting digital security right, and it still isn’t.
As for actual technical issues, the obvious one is that it can be brute-forced (as we just showed) easily. I produced the list of all 5-letter combinations produced from all possible integers in a few hours. Modern GPU processing can perform many millions of these calculations per second. Another technical fault of this would be that collisions are all too easy, as demonstrated by our duplicates. A good encoding should only generate the hashed value from the input, not any other input. MD5 has this flaw. If you were to try and use this encoding to validate a message (say, the integer represents a checksum of the message contents, encoded as a difficult to predict word) then it would be far too easy for a malicious entity to produce the same word from their own message padded out with junk data.
So, not very useful for encryption/hashing (not that it should be). I don’t really have a useful application for this apart from the riddle at the start of this post, but it’s been an interesting journey through optimisation, parallelisation, filtering, and file input/output. I’d say that has made it worthwhile enough.
The data file of valid Scrabble words can be downloaded here if you’d like it. I’ll gladly provide the full 5-letter list on request.
I’m not a data-security expert so any and all of my advice there is liable to be rubbish. Do you know a better way to generate this data, or an aspect I haven’t considered? Hit the comments and let me know.
Title image: CC-BY U.S. Department of Agriculture
devtools::session_info()
## ─ Session info ──────────────────────────────────────────────────────────
## setting value
## version R version 3.5.2 (2018-12-20)
## os Pop!_OS 19.04
## system x86_64, linux-gnu
## ui X11
## language en_AU:en
## collate en_AU.UTF-8
## ctype en_AU.UTF-8
## tz Australia/Adelaide
## date 2019-08-13
##
## ─ Packages ──────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 3.5.2)
## backports 1.1.4 2019-04-10 [1] CRAN (R 3.5.2)
## blogdown 0.14.1 2019-08-11 [1] Github (rstudio/blogdown@be4e91c)
## bookdown 0.12 2019-07-11 [1] CRAN (R 3.5.2)
## callr 3.3.1 2019-07-18 [1] CRAN (R 3.5.2)
## cli 1.1.0 2019-03-19 [1] CRAN (R 3.5.2)
## colorspace 1.4-1 2019-03-18 [1] CRAN (R 3.5.2)
## crayon 1.3.4 2017-09-16 [1] CRAN (R 3.5.1)
## desc 1.2.0 2018-05-01 [1] CRAN (R 3.5.1)
## devtools 2.1.0 2019-07-06 [1] CRAN (R 3.5.2)
## digest 0.6.20 2019-07-04 [1] CRAN (R 3.5.2)
## dplyr 0.8.3 2019-07-04 [1] CRAN (R 3.5.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 3.5.2)
## fs 1.3.1 2019-05-06 [1] CRAN (R 3.5.2)
## ggplot2 * 3.2.1 2019-08-10 [1] CRAN (R 3.5.2)
## glue 1.3.1 2019-03-12 [1] CRAN (R 3.5.2)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 3.5.2)
## htmltools 0.3.6 2017-04-28 [1] CRAN (R 3.5.1)
## knitr 1.24 2019-08-08 [1] CRAN (R 3.5.2)
## lazyeval 0.2.2 2019-03-15 [1] CRAN (R 3.5.2)
## magrittr * 1.5 2014-11-22 [1] CRAN (R 3.5.1)
## memoise 1.1.0 2017-04-21 [1] CRAN (R 3.5.1)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 3.5.1)
## pillar 1.4.2 2019-06-29 [1] CRAN (R 3.5.2)
## pkgbuild 1.0.4 2019-08-05 [1] CRAN (R 3.5.2)
## pkgconfig 2.0.2 2018-08-16 [1] CRAN (R 3.5.1)
## pkgload 1.0.2 2018-10-29 [1] CRAN (R 3.5.1)
## prettyunits 1.0.2 2015-07-13 [1] CRAN (R 3.5.1)
## processx 3.4.1 2019-07-18 [1] CRAN (R 3.5.2)
## ps 1.3.0 2018-12-21 [1] CRAN (R 3.5.1)
## purrr 0.3.2 2019-03-15 [1] CRAN (R 3.5.2)
## R6 2.4.0 2019-02-14 [1] CRAN (R 3.5.1)
## Rcpp 1.0.2 2019-07-25 [1] CRAN (R 3.5.2)
## remotes 2.1.0 2019-06-24 [1] CRAN (R 3.5.2)
## rlang 0.4.0 2019-06-25 [1] CRAN (R 3.5.2)
## rmarkdown 1.14 2019-07-12 [1] CRAN (R 3.5.2)
## rprojroot 1.3-2 2018-01-03 [1] CRAN (R 3.5.1)
## scales 1.0.0 2018-08-09 [1] CRAN (R 3.5.1)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 3.5.1)
## stringi 1.4.3 2019-03-12 [1] CRAN (R 3.5.2)
## stringr 1.4.0 2019-02-10 [1] CRAN (R 3.5.1)
## testthat 2.2.1 2019-07-25 [1] CRAN (R 3.5.2)
## tibble 2.1.3 2019-06-06 [1] CRAN (R 3.5.2)
## tidyselect 0.2.5 2018-10-11 [1] CRAN (R 3.5.1)
## usethis 1.5.1 2019-07-04 [1] CRAN (R 3.5.2)
## withr 2.1.2 2018-03-15 [1] CRAN (R 3.5.1)
## xfun 0.8 2019-06-25 [1] CRAN (R 3.5.2)
## yaml 2.2.0 2018-07-25 [1] CRAN (R 3.5.1)
##
## [1] /home/jono/R/x86_64-pc-linux-gnu-library/3.5
## [2] /usr/local/lib/R/site-library
## [3] /usr/lib/R/site-library
## [4] /usr/lib/R/library